Abstract
Many multimodal systems are really bi-modal or perhaps tri-modal. With the rising interest in applications that span even more modalities all at once, it becomes increasingly important to have large, high-quality datasets that also spans more modalities. This work presents the largest and the highest quality dataset of five modalities. The dataset has three parts. i) A large, >100M sample, automatically generated dataset of quintuples consisting of matching (caption, image, video, audio, and point clouds); ii) a human-rated subset comprising ~1M ratings of pairs amongst the five modalities; and iii) a novel, first-of-its-kind, consensus-based evaluation set (3.5K data points) to evaluate zero-shot capabilities between audio and point clouds. With the release, we hope to accelerate the development of truly multimodal applications. To demonstrate the usefulness of the dataset, we publish a simple, yet powerful, baseline model that demonstrates strong cross-modal retrieval performance. While powerful, the model leaves substantial headroom for further optimization. To name but a few, attention over full token sequences, quality-weighted objectives, and expanded fine-tuning.
Dataset Composition
The dataset is pairing data from five modalities: audio, image, video, point cloud, and text. Each pair is a 5-tuple of a caption and an item from one of the four other modalities.
“A snake is on display, with the sound of a man talking.”



Example of a dataset quintuple: Caption, Audio (snake whispering), Image, Video, Point Cloud, all describing/modally representing the same underlying concept.
The dataset aims to account for both scale and quality. The large pre-training pool is automatically generated from public data sources and aims for quantity. The post-training subset is carefully curated by human annotators to ensure quality. We envision that this dataset can be used for multiple applications, including but not limited to: Cross-modal retrieval models, Multimodal GenAI models, Context aware LLMs, and PhysicalAI.
Pre-training pool >100M
We aggregate ~6.7M captions from public captioning datasets, then match them, per modality, via nearest-neighbor retrieval in modality-specific embedding spaces (e.g., EvaCLIP for images/video, CLAP for audio, and Uni3D for point clouds). For each caption we retrieve top-16 candidates per modality, forming scalable 5-tuples of a caption and four retrieved data items. Here is where we sourced the data from:
Number of data items sourced for each index.
Post-training subset 1M
To elevate the quality, we sample 1M pairs from the pre-training pool for humans to rate. To counter popularity bias and mismatches from automated retrieval, we employ multiple techniques to select a good subset:
- We apply hierarchical clustering for selecting a subset of diverse captions to ensure long-tail coverage
- We apply a greedy, graph-based sampling mechanism to avoid sample overlaps.
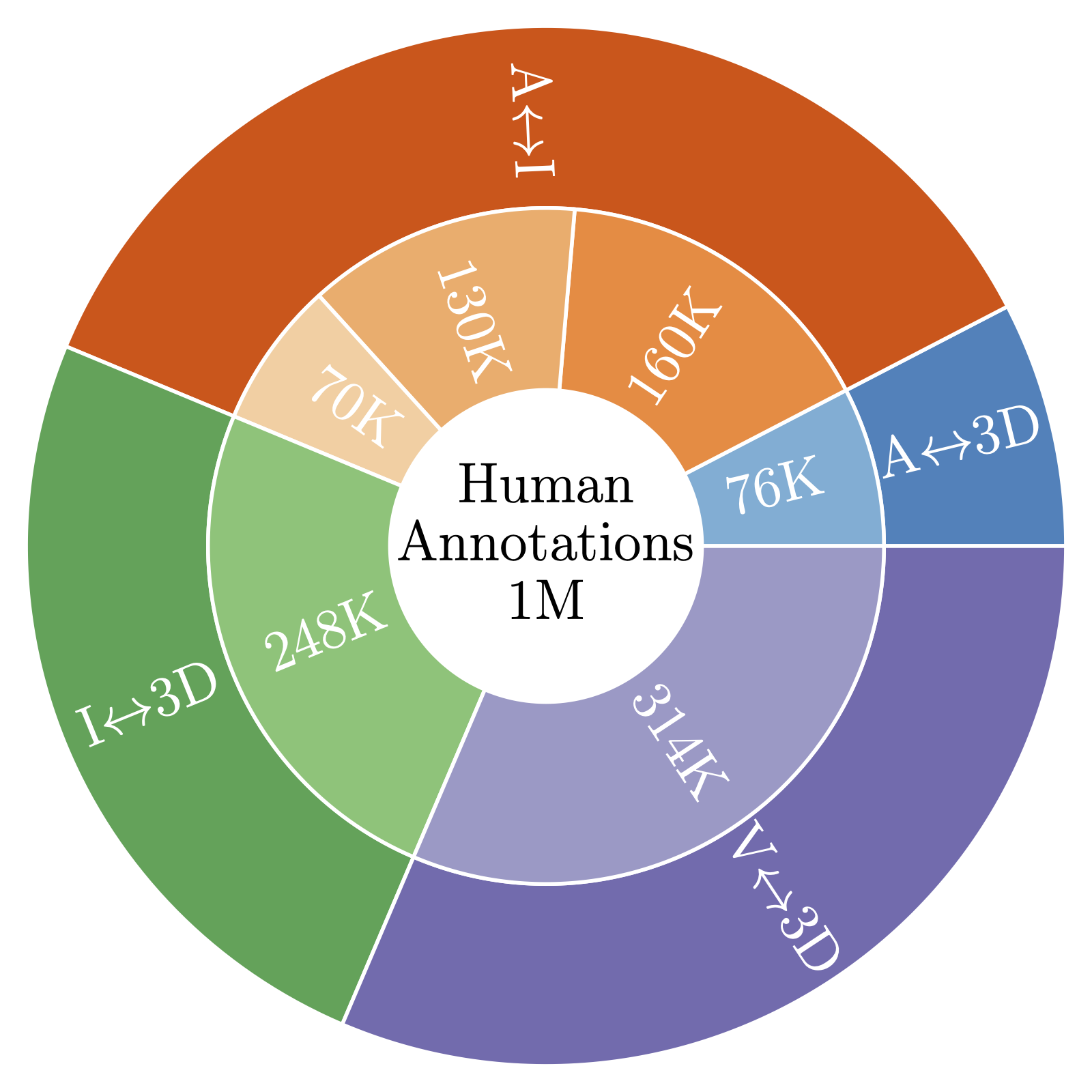
Number of human ratings for each modality pair.
Zero-shot classification benchmark 3.5K
As there exists no public evaluation dataset for audio-point cloud retrieval, we further publish a new, first-of-its-kind evaluation dataset to evaluate audio-point cloud retrieval models. To ensure the lowest possible error-rate within the dataset, we use a consensus-based approach among 5 annotators to ensure that each evaluation item is correct.
While the pre- and post-training datasets are composed on training data from other sources, the evaluation dataset is solely composed of evaluation examples from other datasets. This ensures that this new evaluation dataset does not conflict with existing evaluation datasets and models.
Data Health & Governance
To make the dataset as easily usable as possible, we take multiple measures to clean the data.
- Integrity checks: Corruption detection, duration/shape sanity, and caption deduplication.
- Responsible content: NSFW filtering of data shown for human annotators.
- Licensing: We report all licenses of all underlying datasets to give AI developers full visibility.
- Leakage controls: Known public eval items are excluded from training partitions to protect benchmark validity.
Baselines
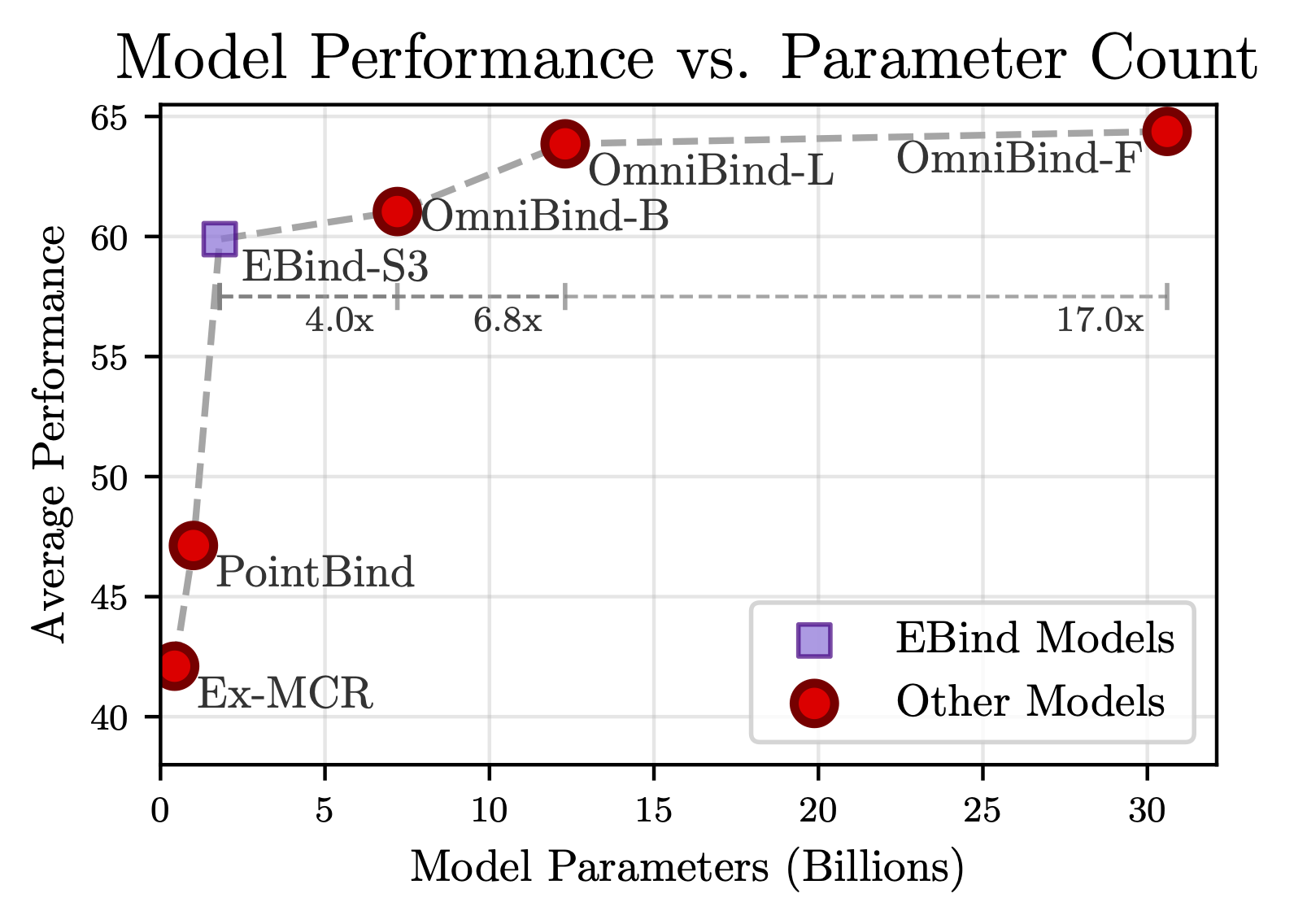
Performance of our baseline model on 13 existing multimodal retrieval and zero-shot classification benchmarks.
We provide a baseline embedding model that can embed all five modalities into one common embedding space. The model is trained with the dataset structure:
- Pre-training: We train the model with a contrastive loss on the large automated pairs and establish a strong cross-modal retrieval baseline.
- Post-training: Fine-tuning on the quality-rated subset delivers consistent gains - notably on object-to-audio retrieval where signals co-occur but are easy to misalign.
While our model is good across an average of 13 benchmarks, especially for its size, it leaves room for improvement. Leverage the full context from token sequences (rather than the CLF tokens only), backport learnings from the 1M annotations to the 107M groups to improve data quality, use quality-weighted objectives, or leverage data augmentations. Or, you could make completely new applications from the data set.
Get Started
- Download the partitions you need (pre-training / post-training / evaluation) from GitHub.
- Prototype quickly with the precomputed embeddings.
- Train: Pre-train broadly, then fine-tune on the verified subset.
- Evaluate: Use our zero-shot classification benchmark to evaluate your model.
Baseline code and training configs will be included for reproducibility.